1. Click on three dots at the top left, then click on Settings

2. Search for "clear," then click "Clear browsing data."

3. Choose which data to clear, then click "Clear data."

1. Click on three dots at the top left, then click on Settings
I asked AI Content Detector to check if the content was generated by a human or by AI. The Detector failed. Here is what I did.
First, I asked GPT4, "What would it take to avoid detection as being an AI generated content?" It gave me a list of items. I asked my question here.

Then I asked it to generate some content using its own advice.
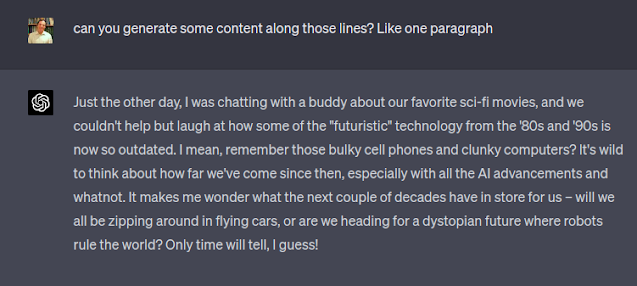
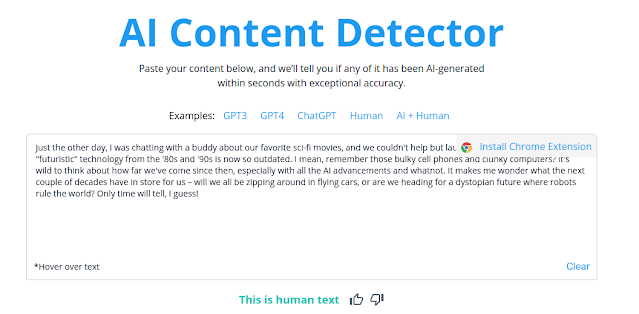
Now, I copied and pasted this text into the AI Content Detector.
At that, AI passed with flying colors, and the AI Content Detection confidently declares, "This is human text."
What are the teachers to do? I mean, how do they distinguish whether the student wrote his work or the AI did. As a joke, I can suggest the AI would do it better. But then it can imitate a bad student as well.
A better advise comes from the CEO of OpenAI, creator of ChatGPT. According to Sam Altman, the teaching process will have to change. The teacher will spend more time interacting with the students and teaching them. A practical advice: ask the student in class to outline their ideas, and they can expand on them at home. Keep in mind that the expansion may come from ChatGPT.
Because of my interest in quantum computing, here are my favorite books on quantum physics. Of course, I am very much indebted to Olivia Lanes, but I also added some of my own.

Quantum Entanglement by Jed Brody.
The most modern of the list, a PDF is easily found on the web, and the book is free on Audible! It is published in the MIT press essential knowledge series, which is always very good.

Fun read. Superheroes take on quantum physics.

With characters are Enshteinish and Schrodinger Cat.

Quantum Physics - what everyone needs to know.
Serious and very clear. In 2015, has a chapter on quantum computing and what such quantum computers would do if they ever exist. Now they do!!

A popular explanation from Cambridge - technical enough. But if you are interested in quantum computing, light reading does not suffice.

Finally, a textbook for students, with formulas and exercises.
The best (others are also good)
https://www.amazon.com/Quantum-Computation-Information-10th-Anniversary/dp/1107002176

I am a Google trainer, and I failed the re-certification exam after four years of teaching. Now I am done with this embarrassing confession. I asked my colleagues, also trainers. Here I am collecting their advice, with my comments.
Recently, I taught a class about Search and Elastic. As part of this class, I gave the students a lab showcasing FreeEed as an example of a real-world application. Here is the lab which you might find helpful as well
https://github.com/elephantscale/elastic-labs/blob/master/integrations/1-FreeEed.md
Enjoy!
Advertised as "Your AI Pair Programmer," GitHub Copilot indeed works very well, and I am impressed. The promise is that "you write the comments, and it writes the implementation code." I did not read this documentation but just started writing code. It worked like magic.
I got a value from a hash table. It offered to check that the value existed and was not empty. The suggestion is shown in the pale font.


An alternate take on why the Solarwinds hack happened (Note: I read and enjoyed the article by Matt Stoller that is linked in the piece): https://www.nytimes.com/2021/02/23/opinion/solarwinds-hack.html?referringSource=articleShare
Top 10 Web Hacking Techniques of 2020 (Must read for anyone in the web application security field): https://portswigger.net/research/top-10-web-hacking-techniques-of-2020
Interesting development in cyber insurance field, led by Google: https://cloud.google.com/blog/products/identity-security/google-cloud-risk-protection-program-now-in-preview
Short post on bots plaguing the online limited-edition sneaker industry: https://threatpost.com/yeezy-sneaker-bots-boost-sun/164312/
Ransomware threat landscape in 2020 and 2021: https://securityaffairs.co/wordpress/115268/cyber-crime/ransomware-landscape-2020.html
Post from Troy Hunt about a password breach (while it is about a political site, it contains the usual details and in-depth analysis that characterize his posts): https://www.troyhunt.com/gab-has-been-breached/
Exchange Zero Days patched by Microsoft: https://krebsonsecurity.com/2021/03/microsoft-chinese-cyberspies-used-4-exchange-server-flaws-to-plunder-emails/